A Fractal Spreadsheet
6th May 2016

Contents
1 Introduction
This is a quick explanation of how to make a spreadsheet into a fractal – specifically, a Julia set.
First, a bit of background.
The idea of using spreadsheet cells as pixels is one I picked up from Matt Parker. It's quite a neat way of illustrating what a picture really is, and it contains within it the ability to easily move from the numbers to the colours.
I wouldn't consider it particularly mathematical though …
My real goal is to make a fractal by getting lots of people to each do a single calculation and then put them all together somehow. I thought of making a huge grid of squares and getting each person to pick a square, run the Mandelbrot set iteration from their square, and then move to the resulting square. Keep going and either you eventually escape the grid or you get trapped in a loop. Stick a piece of coloured paper on your original square accordingly, and you get the Mandelbrot set.
At this point I need to freely confess that I got a bit confused between my Mandelbrot and Julia sets (easily done) in that I thought one could short-circuit the above in that if the square you move to is already coloured in, you should be able to copy the colour back to your original square. That is, if at any point you land on a square whose fate is known, you can backtrack that fate to your original square. This actually isn't how the Mandelbrot set works, but it is how Julia sets work. So all is not lost.
As part of the plan as to how to achieve this, I thought it would be a good idea to have the people start by doing a small scale example on a computer. It's already in the plan to use spreadsheets for other parts of the activity, so using spreadsheets for this seems a good idea1.
1I'm coming round to spreadsheets as a programming environment. I think they have some potential as a way to do quick programming without it feeling like Real Programming.
Incidentally, the idea of getting lots of people to do something simple and then put it all together into something no longer simple owes a lot to the various constructions of Menger sponges and the like as promoted by, you've guessed it, Matt Parker.
But first, of course, I had to try it out for myself to see how it worked. And, though I say it myself, it turned out rather more successfully than I expected.
2 Play it Again, Julia
Let's start with a brief introduction to Julia sets. This isn't meant to be a definitive guide, but just enough to get the idea of what the spreadsheet is doing.
The key to a Julia set is iteration. We have a process with the property that its output can be fed back into it again. A really simple example would be "add ". We also need a starting point, such as . Then we keep applying the process, in this case producing the sequence:
For a Julia set, we're interested in the eventual fate of the sequence. In this case, wherever we start we end up in the same place: zooming off to "infinity". But other processes have more interesting behaviour. If the process is "square it", then at various starting points we have:
So here we have a variety of behaviours. If then the sequence diverges. If then it becomes constant at . Lastly, if then it converges to .
We can be as discerning as we like, but for this then we'll just distinguish between the two most different: either it goes off to "infinity" or it doesn't. The Julia set is the set of those that don't, so for this process it is the set .
Given a process, to find its Julia set we simply pick points in turn and follow their trajectories until their destiny is clear.
One advantage with Julia sets over other kinds of iterative processes is that because the process is always the same, if a particular trajectory eventually coincides with one whose fate is already known, the two share the same fate.
Let's now look at the particular process of the most renowned Julia sets. This is a family of processes, dependent on a parameter. There's one slight wrinkle: we're not dealing with real numbers any more but with complex ones. If you haven't met complex numbers, that's not actually important: just think of real numbers in the following. The process we're interested in is:
where is the parameter.
If then this is our squaring map of earlier and it is quite easy to study. As moves out from the behaviour gets complicated and the Julia set gets more and more intricate. Then as it gets larger still, the Julia set fragments2.
2One definition of the Mandelbrot set is that it classifies those parameters where the Julia set is "nice".
Let's make this real. Complex numbers are convenient here, but we can work as easily with pairs of real numbers. So our process now works on points in the Euclidean plane. Our parameter is also a pair of real numbers, say . The iteration translates to:
So we pick a point in the Euclidean plane and then apply the above over and over until we know its fate. It turns out that if then the trajectory is guaranteed to diverge, so once our trajectory gets outside that boundary we know its fate.
One way to draw the Julia set is as follows. For each point with we calculate its next step. If that step is outside the circle we know that the trajectory leaves and that point is not in the Julia set so we mark all those points. Next we look for points whose next step is one of the marked points, because then we'll know that those points will leave after two hops so we mark those new points. Then we do it again, and again, and again, until we decide that enough is enough. All unmarked points are then our best approximation to the Julia set.
We can make our picture look a little more pleasing by colouring the points according to how long it takes them to escape.
3 Making the Sheet
It took a few iterations (ha ha) to get it how I liked. This isn't the place for a long tale of how I got to where I got, but I'll try to explain it a bit as I go through.
The first bit is probably the most important. While it would be possible to put the full formula needed in each cell, it quickly becomes unwieldy. So some way of storing calculations is needed, and fortunately that's what spreadsheets are good at. To keep the data aligned, I decided to use separate sheets for the different pieces of information that I wanted to store. For each cell, we compute the target cell (i.e., the result of the process applied to the coordinate represented by that cell) and store that. So the spreadsheet has four sheets:
-
Julia Setwhere the final picture will be displayed. -
Xwhich contains the –coordinate of the target cell of each cell. -
Ywhich contains the –coordinate of the target cell of each cell. -
Pwhich contains the parameter and any other useful information.
Each cell in the Julia Set spreadsheet represents a point in our Euclidean plane, but because we want to focus our attention on the square we need to map the cell coordinates to Euclidean coordinates and for that we need to know the size of the spreadsheet. There doesn't seem to be a spreadsheet function that gives the size of the sheet so I hard-coded this in the P spreadsheet. The formulae allow for different horizontal and vertical resolutions. The other thing in the P sheet is the parameter which is – for us – a pair of real numbers. Thus sheet P looks like Table 1 (I'll explain cell B4 later).
A |
B |
C |
D |
E | |
1 |
Parameter | Scaling | Shift | Size | |
2 |
X | -0.2 | =(E2+1)/4 |
=(E2+1)/2 |
52 |
3 |
Y | 0.7 | =(E3+1)/4 |
=(E3+1)/2 |
52 |
4 |
=-1/(2-sqrt(sumsq(B2:B3))) |
The scaling and shift tell us how to transform a cell's coordinates into Euclidean coordinates. If is the scale factor and the shift, the formula is . We'll also use the inverse which is . As said above, we could use different scale factors and shifts for the vertical and horizontal directions but for simplicity in the following we'll assume that they're the same.
For a cell with column and row , the corresponding coordinates in Euclidean space are:
Then we apply the process to get the Euclidean coordinates of the target point:
Finally, we transform it back into cell coordinates:
There's one little wrinkle in that these last coordinates need to be integers so we round them.
The spreadsheet formulae for and from and are:
=ROUND((((COLUMN(A1) - P!$D$2)/P!$C$2)^2-((ROW(A1) - P!$D$3)/P!$C$3)^2 + P!$B$2)*P!$C$2 + P!$D$2)
=ROUND(((2*(ROW(A1) - P!$D$2)/P!$C$2)*((COLUMN(A1) - P!$D$3)/P!$C$3) + P!$B$3)*P!$C$3 + P!$D$3)
Let's decompose that a little. The spreadsheet functions involved are:
-
COLUMN()gets the column number of a cell, -
ROW()gets the row number of a cell, -
ROUND()does the rounding at the end.
The cells P!$D$2 and so on refer to the various parameters and other precalculated numbers in the parameter sheet.
The simplest way to fill the sheets is to enter these formulae as written in cell A1 of each of the X and Y sheets respectively and then copy them into the entire sheet. This will also, due to the magic of spreadsheets, change the A1s in the formulae in each cell to match the specific cell.
Now we turn to the sheet Julia Set itself. In a given cell, we look up the target cell by looking in the corresponding entries in the X and Y sheets. We test to see if that cell is outside the range. If it is, we mark the cell. If not, we copy the the contents of the target cell into the original cell. The formula for this is:
=if(sumsq((X!A1 - P!$D$2)/P!$C$2, (Y!A1 - P!$D$3)/P!$C$3) > 4, "" ,indirect("R" & Y!A1 & "C" & X!A1,false) )
The result of this is interesting. If a cell escapes, it is blank. If it doesn't escape, it eventually gets into a loop. The spreadsheet is sophisticated enough to detect this and marks those cells with an error message which then gets copied back. So the Julia set consists of those cells with an error message.
To colour the escape cells, instead of making them blank we put a number in the cell and then whenever we copy a value from one cell to another we add one to it.
=if(sumsq((X!A1 - P!$D$2)/P!$C$2, (Y!A1 - P!$D$3)/P!$C$3) > 4, 1 ,indirect("R" & Y!A1 & "C" & X!A1,false)+1 )
With this in place, we then use conditional formatting to colour the cells in the sheet according to their value. In Google Sheets, this is done using a Color scale conditional formatting. I found it looks best if the middle colour has a lowish value as the numbers grow exponentially.
The other conditional formatting to apply is to darken the error cells. In Google Sheets, this is done using a Custom formula formatting rule. The formula is:
=ISERROR(A1)
(When applied to the whole sheet, the A1 is a placeholder for each cell in turn.) This doesn't quite colour the error cells completely black as it doesn't hide the red triangle in each one.
The other things to do are to make the individual cells as small as possible. As well as setting the width and height, set the font size to its smallest value. Then zoom out to fit the entire sheet in the window.
The last detail is to smooth out the colour gradient. There is a proper way to do this, but I judged it a bit beyond spreadsheet capabilities so I went for a cheap and cheerful one that is not "correct" but does smooth out the colours. Thus the final formula in the Julia Set is:
=if(sumsq((X!A1 - P!$D$2)/P!$C$2, (Y!A1 - P!$D$3)/P!$C$3) > 4, max(0,1 + P!$B$4*(sqrt(sumsq((X!A1 - P!$D$2)/P!$C$2, (Y!A1 - P!$D$3)/P!$C$3))-2)) ,indirect("R" & Y!A1 & "C" & X!A1,false)+1 )
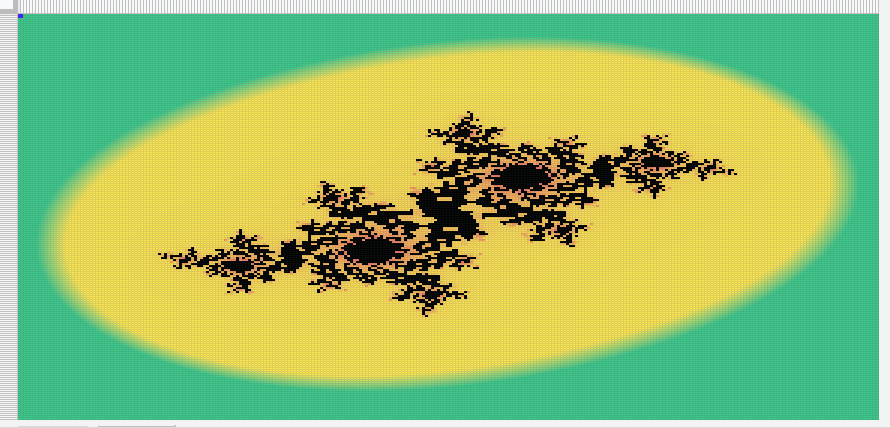
The final result looks something like Figure 1. The spreadsheet itself is available as a Google Sheets document.

4 Update: New Features
Google regularly update Sheets with new features and functions. There have been several since I originally devised this spreadsheet that have improved the outcome considerably.
4.1 Named Ranges
The ability to give a range a name makes it simpler to refer to a cell in a formula by a meaningful alias rather than just a cell reference. The cells that I ended up aliasing are the ones in Table 2, these are the formula or values that don't vary so can be calculated or set once for all.
A |
B | |
1 |
Width | =columns(Fractal!A1:A) |
2 |
Height | =rows(Fractal!A1:1) |
3 |
Real | -.2 |
4 |
Imaginary | .7 |
5 |
Weighting | =-1/(2-sqrt(sumsq(Real,Imaginary))) |
Table 2: The Revised Parameter Sheet
4.2 The Let Function
This is the most versatile new function. The let function provides a way to build up a complicated calculation in small pieces. This makes it possible to have a single formula that contains all the subformulae without it becoming unwieldy and unreadable.
=let(
x, column(A1),
y, row(A1),
sx, (x-1)/(Width-1)*4-2,
sy, (y-1)/(Height-1)*4-2,
jx, sx*sx - sy*sy + Real,
jy, 2*sx*sy + Imaginary,
dsq, jx*jx + jy*jy,
ux, floor((jx+2)/4.000001*Width+1),
uy, floor((jy+2)/4.000001*Height+1),
if(dsq>4,
max(0,
1+Weighting*(sqrt(dsq)-2)
)
),
indirect("R" & uy & "C" & ux,false)+1
)
)
In this formula, we start with as the column and row of the cell. This gets transformed to which are the coordinates in . The Julia set formula, , is encoded in the formulae for . Then is the (squared) distance of this from the origin which is used to test whether the iteration falls off the edge of the spreadsheet. Lastly, transform back into the row and column ranges (the use of ensures that we don't go beyond the sheet's boundaries). Each of these definitions uses (some of) the previously defined variables which is what makes let so versatile.
Then the if at the end does the iterative step, again using some of the predefined variables.
4.3 Customising the Error Values
One of the nice things about using a spreadsheet was the built in iteration. This did, however, lead to a mild irritation with the look of the Julia set. The cells that get caught in a loop are marked as an error, and it isn't possible to remove the marking with conditional formatting. Putting iferror in the formula doesn't work because it isn't the formula that produces the error. However, having a second sheet that picks up the values from the first and wraps them in an iferror does work.
So now I have one sheet that computes the values and a second that simply refers to that first with an iferror wrapping:
=iferror('Julia Set Values'!A1,"")
Then the conditional formatting is set so that blank values are coloured black.
4.4 Resizing
One benefit of having one sheet for the calculations and one for the colours is that the cell size of the calculation sheet can be kept normal, making it easier to see what's going on and edit the formulae. Since I first designed this sheet it also appears that Google now allow smaller cell sizes, meaning that the final image looks even better, as in Figure 2.